Never-Ending Behavior-Cloning Agent for Robotic Manipulation
Abstract
Relying on multi-modal observations, embodied robots could perform multiple robotic manipulation tasks in unstructured real-world environments. However, most language-conditioned behavior-cloning agents still face existing long-standing challenges, i.e., 3D scene representation and human-level task learning, when adapting into new sequential tasks in practical scenarios. We here investigate these above challenges with NBAgent in embodied robots, a pioneering language-conditioned Never-ending Behavior-cloning Agent. It can continually learn observation knowledge edge of novel 3D scene semantics and robot manipulation skills from skill-shared and skill-specific attributes, respectively. Specifically, we propose a skill-shared semantic rendering module and a skill-shared representation distillation module to effectively learn 3D scene semantics from skill-shared attribute, further tackling 3D scene representation overlooking. Meanwhile, we establish a skill-specific evolving planner to perform manipulation knowledge decoupling, which can continually embed novel skill-specific knowledge like human from latent and low-rank space. Finally, we design a never-ending embodied robot manipulation benchmark, and expensive experiments demonstrate the significant performance of our method.
Overview
Algorithm

Methodology
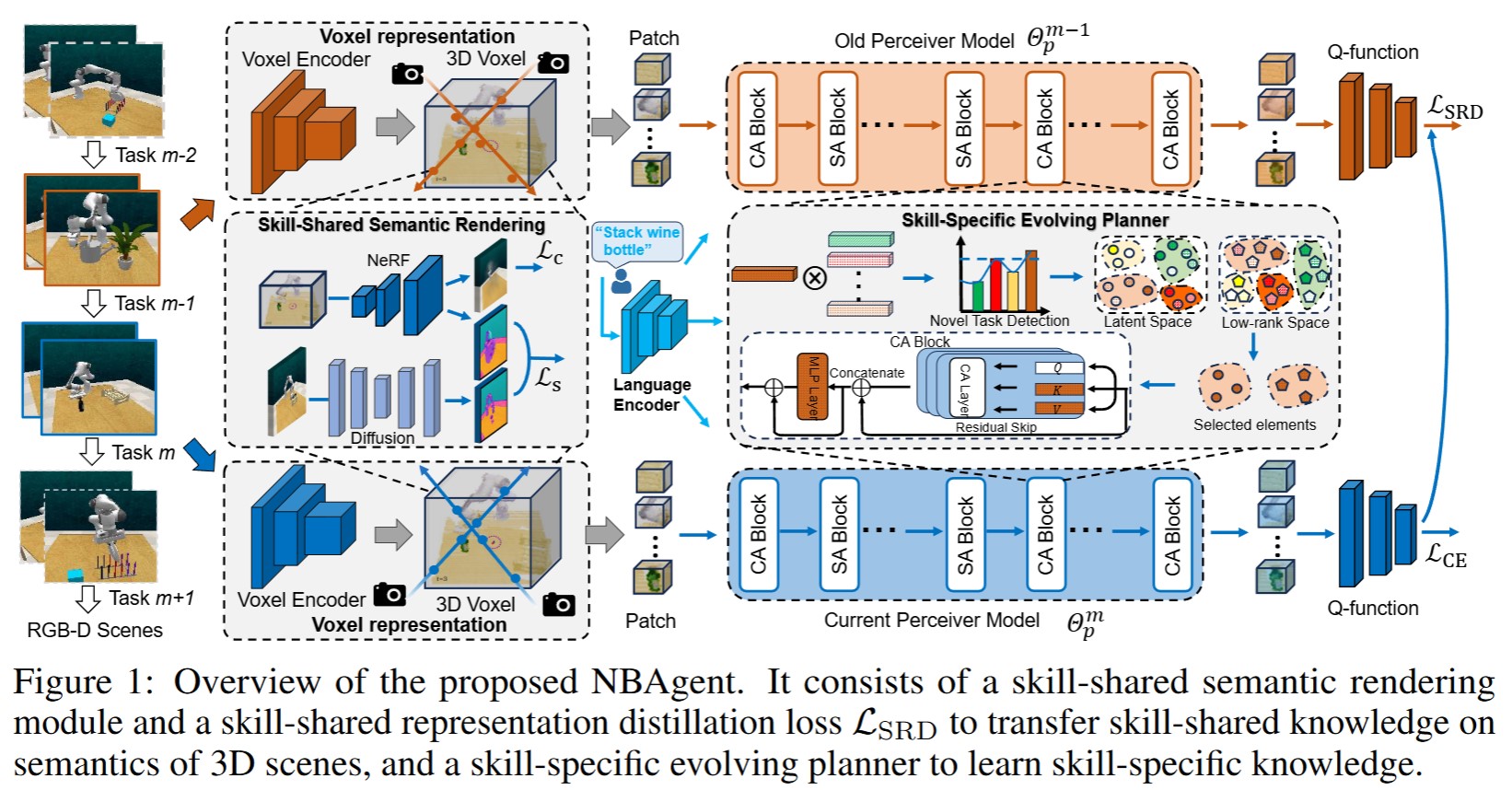
we propose a pioneering language-conditioned Never-ending Behavior-cloning Agent (i.e., NBAgent), which can continually acquire skill-wise knowledge from both skill-shared and skill-specific attributes. To the best of our knowledge, this is an earlier attempt to explore continual learning for multi-modal behavior-cloning robotic manipulation. To be specific, we design a skill-shared semantic rendering module (SSR) and a skill-shared representation distillation module (SRD) to transfer skill-shared knowledge on semantics of 3D scenes. Supervised by Neural Radiance Fields (NeRFs) and a vision foundation model, SSR can transfer skill-shared semantic from 2D space into 3D space across novel and old skills; SRD can effectively distill skill-shared knowledge between old and current models to well align voxel representation. Additionally, we propose a skill-specific evolving planner (SEP) to decouple the skill-wise knowledge in the latent and low-rank space, and focus on skill-specific knowledge learning to alleviate manipulation skill forgetting.
• Skill-Shared Attribute indicates that different complex skills possess shared knowledge, such as similar manipulated objects and 3D
scenes understanding and so on. We primarily investigate the consistency of skill-shared knowledge across various skills on semantics of 3D scenes, which plays a key role in addressing skill forgetting and achieving comprehensive understanding on 3D scenes.
• Skill-Specific Attribute originates from various factors such as distinct manipulation sequences, object recognition, motion primitives, and other distinct elements within each unique skill. Focusing the embodied robot to learn skill-specific knowledge can effectively perform novel skills learning and tackle forgetting on past learned manipulation skills or tasks.
Real-world Results
To verify the effectiveness of our method on real-wolrd robot, we conduct somw experiments on a UR5e robot with a parallel gripper, and collect RGB-D observation by utilizing a front RGB-D camera.
We then design five manipulation tasks to verify the effectiveness of our never-ending method, including 1)stack blocks; 2)place bottles; 3)put block in box; 4)place can; and 5)put bottle in box.
Each task has at least two variations, totaling 13 variations.
To simulate the never-ending behavior-cloning scenario, we conduct a ‘1-1’ setting, where the agent learns 5 skills by five times.
“place bottles“
“place bottles“
“place bottles“
“put bottle in box“
“put bottle in box“
“put bottle in box“
“place can“
“put block in box“
“put block in box“
“put block in box“
“stack blocks“
“stack blocks“
“stack blocks“
“place can“
Simulation Results
We design two NBRL benchmark datasets using RLBench, called Kitchen and Living Room. In particular, we assemble Kitchen by gathering 10 skills that are pertinent to kitchen settings,
and we construct Living Room, which includes 12 skills that are related to living room situations. Each skill includes a training set of 20 episodes and a test set of 25 episodes.
Kitchen: 1)close microwave; 2)meat off grill; 3)open grill; 4)open wine bottle; 5)pick up cup; 6)place wine at rack location; 7)put knife on chopping board; 8)stack wine; 9)take plate off colored dish rack; 10)turn tap.
Living Room: 1)close door; 2)close laptop lid; 3)hang frame on hanger; 4)lamp on; 5)open drawer; 6)open window; 7)push buttons; 8)put item in drawer; 9)put rubbish in bin; 10)sweep to dustpan of size; 11)take usb out of computer; 12)water plants.